注意力机制
处理文本时,传统的 RNN 网络 一个词一个词地往后读,文本太长时,模型试图把整个文本的信息压缩进隐状态 中,必然很容易出现遗忘或信息丢失。
注意力机制解决了这些问题: 它让模型在处理每一个词时,都能“直接看到”整句话的所有词,并根据相关性自己挑重点。
注意力机制的精髓在于三个矩阵:(Query)、 (Key)和 (Value)。
处理一个词汇时,将这个词汇的 Embedding 向量 分别乘以 、 和 得到向量 、、和 。
接下来计算得分,分数决定了在对某个位置的词进行编码时,我们要对输入句子其他部分投入多少关注。
分数的计算方法是:取当前词的 向量 与我们要评分的词的 向量 的点积。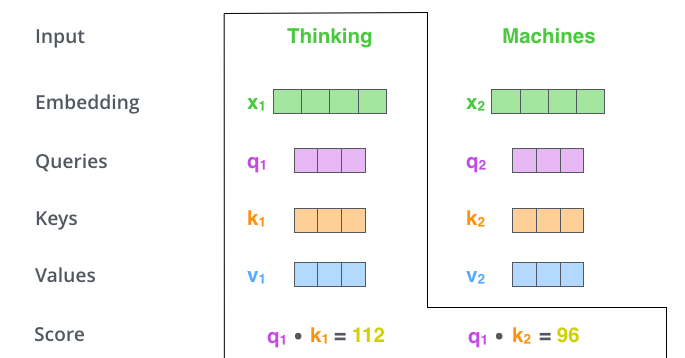
通过 Softmax 操作将分数归一化,然后将每个 向量乘以其对应的 Softmax 分数并求和(也就是加权求和)。到这里便产生了自注意力机制的输出 。
多头注意力机制
“多头注意力” (Multi-Headed Attention) 机制进一步完善了自注意力层。它大大提升了注意力机制关注不同部分的能力。
如果我们进行 次相同的自注意力计算(使用不同的权重矩阵),我们将得到 个不同的 矩阵。
但我们并不希望获得 个矩阵 ,我们的选择是,将矩阵拼接起来,然后乘以一个额外的权重矩阵 。
Transformer 的结构
宏观来说,Transformer 的结构如下图。
输入 -> [编码组件(Encoders)] -> [解码组件(Decoders)] -> 输出 |
编码组件由一组编码器堆叠而成,解码组件则是相同数量的解码器堆叠。
Encoder
编码器在结构上完全相同,但它们并不共享权重。每个编码器包含一个自注意力层和一个前馈层。
前馈层
它由两个线性变换(全连接层)和一个激活函数组成:
前馈层在模型结构中引入了非线性来增强模型的拟合能力,还承担了知识存储的功能,还能增强模型识别语义特征的能力。
在 Transformer 的参数量中,前馈层占据了很大比例,一般在它的中间层会进行升维。
Decoder
掩码自注意力层
它和 Encoder 的自注意力基本一样,但多了一个重要约束:在生成第
个词时,模型只能看到前 个词,后面位置的得分都会被设为 。
交叉注意力层
- :来自 Decoder 上一层的输出(代表“我现在手头已经写了什么,我还缺什么信息”)。
- 和 :来自 Encoder 最后一层的输出(代表原始输入句子的完整语义。)
前馈层
这部分和 Encoder 完全一样。在经历了两轮注意力(关注自己写了什么 + 关注原文说了什么)之后,Decoder 在这一层进行非线性变换和知识提取,准备输出这个位置的最终特征。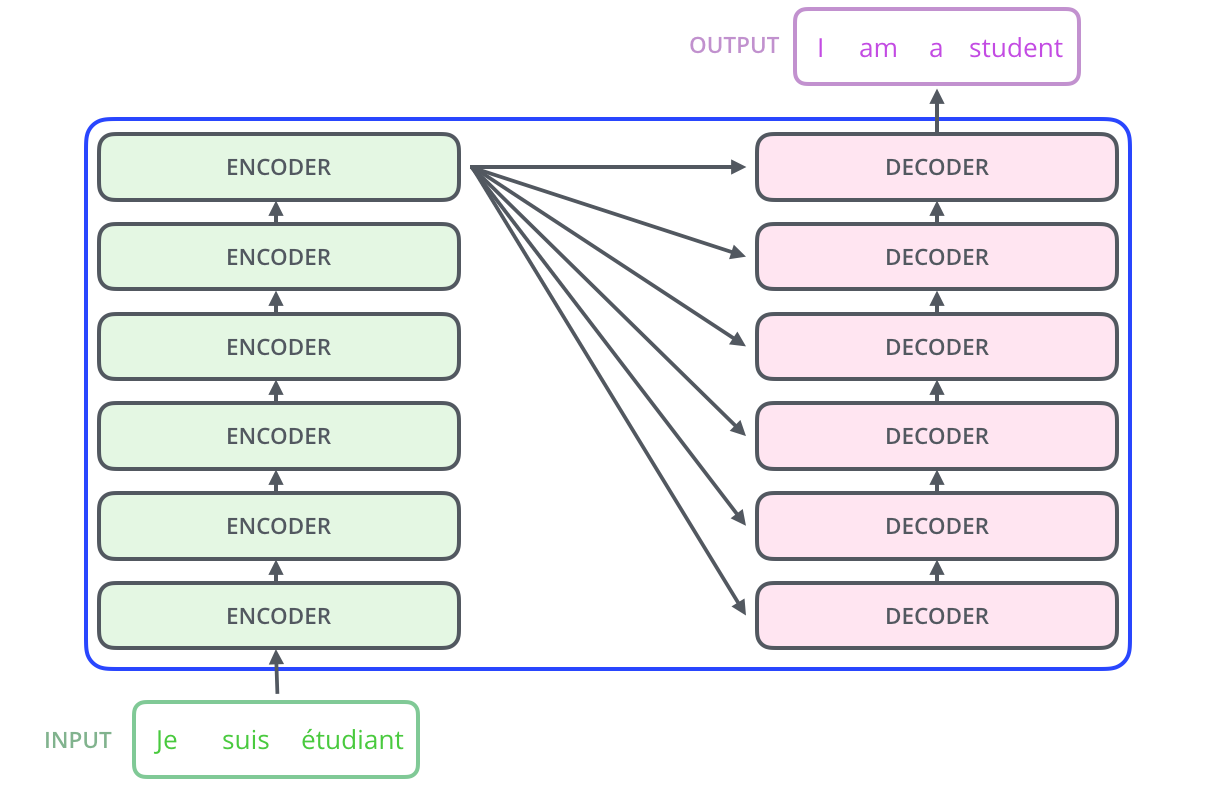
最终输出
Decoder 的最终输出仍然是一个维数为 的向量,
我们使用一个线性层,它是一个简单的全连接神经网络,它将 Decoders 产生的向量投影到一个巨大的向量中,这个向量被称为 Logits 向量,它的维数等于词表大小。
位置编码
到目前为止,模型的描述中还缺少对词汇顺序的刻画,为了解决这个问题,我们直接给词汇的 Embedding 向量加上一个 位置编码向量: